Replacing a simple website can be straightforward. Replacing a business-critical production system with user accounts, orders, invoices, external integrations, and long-running transactions is a different challenge, especially when customers must continue using the service throughout the migration.
In this project, neither the old nor the new system had been developed by us, and the original development teams were unavailable. Before we could design the migration, we first had to understand how both platforms behaved in production and how data moved between them.
Understanding the Legacy Production System
The legacy system accepted customer orders, sent them to an external software-as-a-service platform for consolidation, created accounting records, and notified customers and couriers.
The simplified flow looked like this:
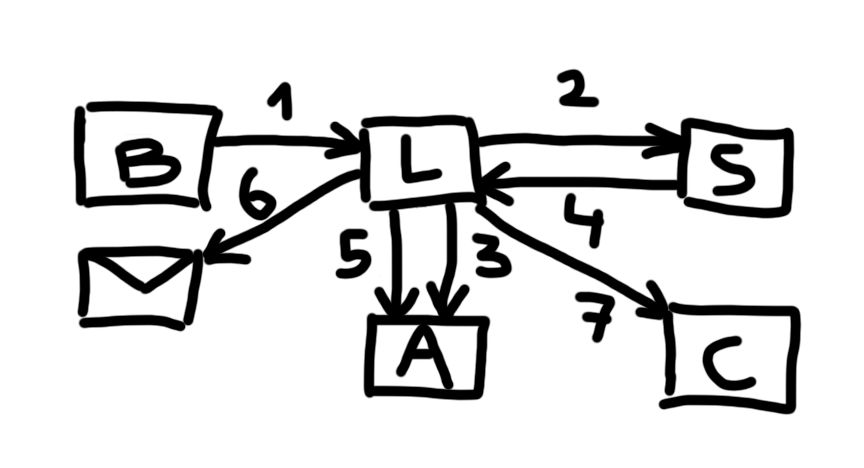
On the diagram, B stands for Browser, L for the Legacy system, S for the SaaS service, A for the Accounting system, and C for the Courier system. The envelope represents the email notification sent to the customer.
The customer placed an order in the Browser, and the order was sent to the Legacy system (step [1]).
The Legacy system sent the order to the SaaS service for consolidation (step [2]).
The data required for the initial debit invoice was sent from the Legacy system to the Accounting system (step [3]).
Customers could order up to seven days in advance, so consolidation might not happen until a week after the order was placed. Once consolidation was complete, the SaaS service sent the result back to the Legacy system (step [4]).
If some of the originally ordered items could not be supplied, the Legacy system sent the information required for a credit invoice to the Accounting system (step [5]).
The Legacy system then sent the customer an email with the final order information and any credit invoice details (step [6]).
At the same time, the Legacy system sent the delivery information to the Courier system (step [7]).
The real production flow involved additional systems, but this simplified model captured the migration-critical dependencies.
The New System and a Shared SaaS Constraint
The new platform supported essentially the same business flow, but it used a different technology stack and database. Both systems depended on the same external consolidation service.
That service could return results to only one configured endpoint. It could not send legacy orders to the legacy platform and new orders to the new platform automatically. This limitation became the central technical constraint of the migration.
Running the New System in Parallel
Before the public switchover, we ran the new system in production under a separate domain with restricted access. Client employees used it with real customers, real orders, and real payments.
Running both systems in parallel gave us a controlled way to test production behavior. It also required routing logic in the legacy platform. Because order identifiers were unique across the two systems, the legacy endpoint could determine where each consolidated order belonged.
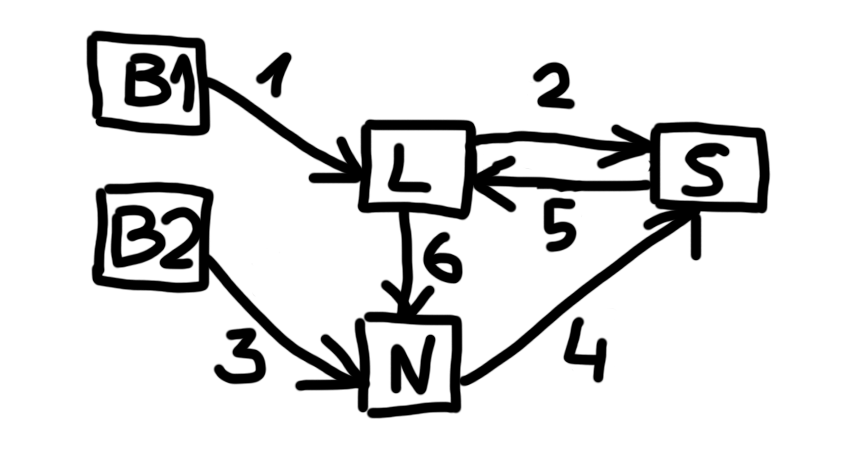
On this diagram, B1 represents the browser using the legacy frontend, B2 represents the browser using the new frontend, L stands for the Legacy system, N for the New system, and S for the SaaS service.
When an order was placed through the legacy frontend, B1 sent it to the Legacy system (step [1]).
The Legacy system then sent the order to the SaaS service for consolidation (step [2]).
When an order was placed through the new frontend, B2 sent it to the New system (step [3]).
The New system sent the order to the same SaaS service used by the legacy platform (step [4]).
After consolidation, the SaaS service returned every result to the Legacy system because it supported only one callback endpoint (step [5]).
A small routing component in the Legacy system checked the order identifier. Results belonging to new-system orders were forwarded to the New system (step [6]), while legacy orders continued through the existing flow.
This temporary bridge let both applications operate simultaneously even though the external provider supported only one callback address.
Migration Requirements
The databases were structurally different, so we needed to migrate customer accounts and selected historical data. We also had to guarantee that every order created before the switchover would still be processed correctly when its consolidation result arrived days later.
That second requirement meant the legacy system could not simply be turned off when customers started using the new one.
Choosing a Migration Strategy
The easiest technical option would have been to stop accepting orders for a week before the switchover. That would have allowed all legacy orders to complete before the new system went live, but it would also have stopped the client's business. It was therefore not a realistic option.
Instead, we planned to keep the systems running in parallel and switch the public domain from the legacy server to the new server through DNS. The expected customer-facing interruption was only a few minutes.
Continuous Data Migration
Before the switchover, we reduced the DNS time-to-live value so that resolvers would pick up the new address quickly.
We then built continuous migration jobs for customer accounts and related data. Conceptually, they ran like this:
while (true) {
migrateUsers()
}
The production implementation was naturally more robust, but the principle was simple: synchronize changes repeatedly before the final cutover. By the time DNS changed, the new database was already up to date, so we did not need a long maintenance window for a one-off migration.
Migrating Passwords Safely
The two systems used different password-hashing algorithms. Passwords could not be converted directly because secure password hashes are not reversible.
We therefore allowed a migrated customer to authenticate with the legacy hash on their first login to the new system. After successful authentication, the password was re-hashed with the new algorithm and stored in the new format. The migration completed gradually without asking every customer to reset their password immediately.
Migrating Useful Historical Data
A complete order-history migration would have been disproportionately complex because the two systems represented orders differently. Instead, we migrated the information that delivered the most practical value: each customer's most frequently ordered products were added to the new system's Favorites feature.
This was a deliberate trade-off. The migration preserved useful behavior without creating a large, risky transformation project for data that was not essential to ongoing operations.
Reversing the Routing After Cutover
After DNS pointed customers to the new system, the external SaaS platform also began returning all consolidation results to the new endpoint. The routing direction therefore had to reverse.
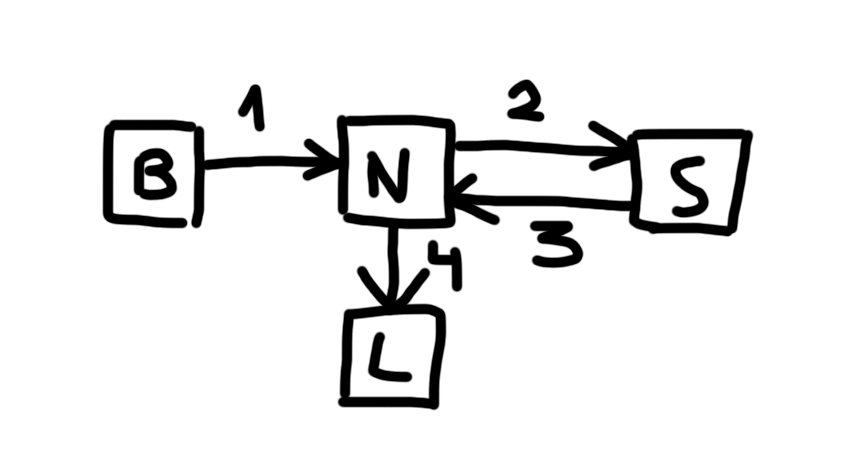
On this diagram, B stands for Browser, N for the New system, S for the SaaS service, and L for the Legacy system.
The customer placed an order in the Browser, and the order was created in the New system (step [1]).
The New system sent the order to the SaaS service for consolidation (step [2]).
After consolidation, the SaaS service returned the result to the New system (step [3]).
The New system checked the order identifier. Results for orders originally created in the legacy platform were forwarded to the Legacy system (step [4]) for invoicing, notifications, and delivery processing. Results for new-system orders remained in the new platform.
Because customers could place orders seven days in advance, this reverse bridge had to remain active for at least a week after cutover.
Planning the Production Cutover
Large releases are often scheduled late at night or at the end of the week. That may reduce traffic, but it also means tired engineers, unavailable stakeholders, and little time to address follow-up issues before the weekend.
We chose a Monday morning during normal working hours. The team was rested, the necessary people were available, and the rest of the week remained open for monitoring and fixes. The client initially preferred a night release, but we persuaded them that daytime availability reduced operational risk.
The day before the change, we placed a banner in the legacy application warning customers about the short interruption. On Monday, we updated DNS and the new system became the public production platform.
Because both frontends were single-page applications, customers who already had the legacy site open needed to refresh their browsers before loading the new application. Customers in the middle of building a shopping cart also lost its contents; migrating those temporary sessions would have added unreasonable complexity for limited benefit.
Only a small number of support requests were directly related to the cutover. Some customers reported minor defects or preferred aspects of the old interface, but the core service remained available and the planned downtime stayed within a few minutes.
Unexpected Problems During the Release
No major migration is completely predictable.
An ISP Ignored the DNS Change
One of Estonia's largest internet service providers continued serving the old DNS result for up to three hours, despite the reduced TTL. Other resolvers updated correctly, and we found no defect in our DNS configuration.
The provider denied responsibility, but the practical result was that some customers continued reaching the legacy system longer than planned. The parallel-operation and routing design helped contain the impact.
A Production Memory Leak
A second surprise was a significant memory leak in the notification component responsible for customer email and SMS messages.
That functionality had been disabled during performance testing because sending real notifications would have created unnecessary cost for the client. As a result, the leak did not appear in the test environment. Once the feature ran at production volume, monitoring charts revealed the problem quickly and gave us enough information to respond.
The incident reinforced an important lesson: realistic testing matters, but observability is equally important because not every production behavior can be reproduced safely in advance.
Stabilization and Decommissioning
The days after the release produced a number of minor customer-reported issues, but nothing that stopped the client's business.
This was reassuring because the new application's codebase had not been written by us and already contained several signs of weak engineering practices. We could not guarantee that deeper problems did not exist. After the migration, we continued improving the system by removing unused code, correcting defects, and developing new features.
A few weeks later, all legacy orders had completed. We deleted the temporary migration and routing code and shut down the old platform completely. Removing the bridge code was an important final step: temporary migration infrastructure should not become a permanent source of complexity.
Lessons From Replacing a Legacy System
The difficult part of this project was not writing a large amount of code. The temporary synchronization, password migration, and routing components totalled only a few hundred lines.
The real work was understanding the business process, identifying the long-running dependencies, choosing where those few lines belonged, and designing a cutover that protected customers and revenue.
Projects like this cannot be specified as a simple list of development tasks. The client can define the goal of replacing the old platform, but the technical team must discover how to reach it safely. That requires close collaboration with people who understand the business process in detail.
The migration succeeded because we reduced the final release to a small, reversible infrastructure change after weeks of parallel operation and continuous synchronization. The result was a new production system with only a few minutes of planned downtime and minimal disruption to end customers.

